

Kubernetes, also known as K8s (where 8 represents the number of letters between K and S!) is the most widely used and trending open-source tool nowadays. It is a system used for automating the deployment, scaling, and management of containerized applications.
Why use K8s?
Kubernetes is a powerful tool to use if you are building cloud-native applications with numerous microservices. It provides a lot of out-of-the-box features that make deployment and monitoring easier (when compared to installing and managing applications directly on physical/virtual machines), and with more power than a single container runtime such as Docker.
- Service Discovery and Load Balancing: Kubernetes can expose a container using the DNS name or using their own IP address.
- Self-healing: Auto-healing is a great feature that Kubernetes provides — it restarts, kills, and replaces containers that fail.
- Automated Rollouts and Rollbacks: Microservice systems could include hundreds, if not thousands, of services that can be hard or impossible to spin up manually. With this feature, you’re able to specify the desired state of a given application (deployment) and Kubernetes will do the work to make sure to achieve this state.
- Secret/Config Management: This allows you to store config and sensitive data like passwords, tokens, and SSH keys.
- Auto Resource Management: Specify the resource, RAM, and CPU, needed for your deployments, and Kubernetes will distribute containers to relevant nodes, and fit them for optimal use of machine resources.
- Storage Orchestration: Kubernetes allows you to automatically mount a storage system of your choice, such as local storage or from public cloud providers.
K8s Architecture
When you deploy Kubernetes, you get a cluster. A K8s cluster consists of many different components, as illustrated in the diagram below.
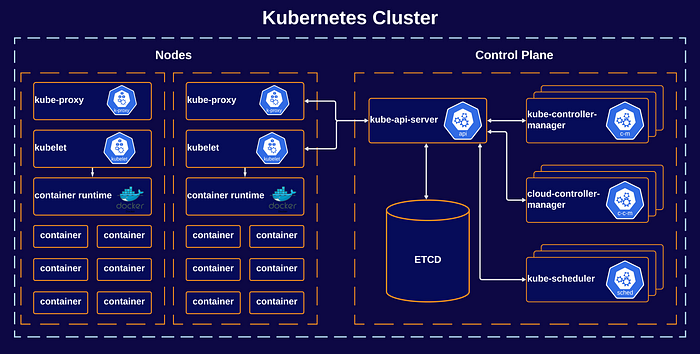
Control Plane
The Control Plane or (Master Node) controls your K8s cluster, and it consists of multiple components that are responsible for managing that cluster. Usually, all the components are installed on the same machine for simplicity, but of course control plane components can be distributed among machines within the cluster. The main components that form K8s and are related to your control plane are:
- kube-api-server: Interacting with K8s cluster is done through the kube-api-serer which is the primary interface to the control plane and the cluster.
- etcd: A key-value store that K8s uses as its data store for the cluster. It is highly available and reliable storage for fast data access and retrieval.
- kube-scheduler: When creating and running containers, kube-scheduler makes sure to select the right available node to run the container.
- kube-controller-manager: Contains multiple logical controllers that handle the state of K8s objects. Some of those controllers are node-controller, job-controller, and service-account-controller.
- cloud-controller-manager: Provides an interface between K8s and different cloud platforms. It’s only used when using cloud-based resources alongside K8s.
Nodes
One or more nodes can be installed, whether it be on a virtual or physical machine, depending on the cluster. Each node is managed by the controlplane, and contains the necessary services to run pods and communicate directly with the control plane. These are made up of:
- kubelet: An agent that runs on each node––it communicates with the control plane to ensure that the containers run on the node as required by the control plane. Also, it reports back the state of the running containers to the control plane.
- kube-proxy: A network proxy that runs on each node and that handles network rules on nodes. These network rules allow network communication between your Pods, from network sessions inside or outside of your cluster.
- container runtime: The container runtime is the software that is responsible for running containers: you need to install a container runtime in each node within the cluster so that Pods can run there. K8s supports several container runtimes, the most popular of which are Docker & containerd.
Installing a K8s Cluster
There are many ways to install K8s cluster for production, either on-premise, or you can choose from many of the available public cloud K8s services, like AKS from Microsoft Azure, or GKE provided by Google Cloud. Deciding on these will depend on what your cluster needs, as well as the requirements, use case, and project you are working on.
I will mention some ways to spin up a local K8s cluster for you to play around with and start getting familiar with starter K8s concepts––after all, we learn better when we get our hands dirty! 🔨 💻
- Kind: Kind is a simple tool to create and manage a local Kubernetes cluster––I advise you to start with it for its simplicity, and it uses Docker for spinning up the cluster.
- minikube: Another Kubernetes SIG project, but quite different when compared to Kind. Kind is faster and lighter, so don’t use minikube if you have limited resources on your machine.
- Kubeadm: Kubeadm is a tool built that provides
kubeadm initandkubeadm joinfor starting master and worker nodes. - The hard way: if you are a confident CLI user and appreciate a good challenge, this part includes installing your Kubernetes cluster from scratch, though you will need a GCP account.
- K3s: A certified Kubernetes distribution, which is highly available and lightweight with less than 40MB binary, that reduces the dependencies and steps needed to install, run and auto-update a production Kubernetes cluster, making it a great option for deploying to IoT and edge devices.
Kubectl — The CLI
Before diving through the main K8s objects, it is good to cover the tool we will use for accessing the cluster: kubectl. It uses the Kubernetes API to communicate with the cluster and carry out commands––believe me, it is better than using curl.
Here, we’ll cover some of the most frequently used commands you’ll need:
- kubectl get: lists objects within the Kubernetes cluster.
$ kubectl get <object type> <object name> -o <output> --sort-by <JSONPath> --selector <selector>- kubectl describe: get detailed information about a given object.
$ kubectl describe <object type> <object name>- kubectl create: to create objects by providing a YAML file, with -f to create an object from a YAML descriptor stored in the file.
$ kubectl create -f <file name>- kubectl apply: same as create, but will update the object if it exists. It also stores the last-applied-configuration annotation.
$ kubectl apply -f <file name>- kubectl delete: delete objects from the cluster.
$ kubectl delete <object type> <object name>Imperative vs Declarative
Usually, for creating objects in K8s we use the declarative method which requires creating a YAML file and run this command to do the job:
Kubectl apply/create/delete -f file.yamlThis method allows us to keep a history of our K8s manifests and have them in a repository, following more of an Infrastructure as Code approach.
However, sometimes you need to be quickly spinning things up using kubectl directly to experiment, or resolve an issue––imperative commands are handy for doing this. Here, you are also able to generate a YAML file if you are not very familiar with K8s manifest definitions. Below are some of useful imperative commands with their outputs.
- Run a pod with nginx container:
$ kubectl run nginx --image=nginx
pod/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 58s- Generate YAML template for a pod without running it:
$ kubectl run nginx --image=nginx --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}- Generate nginx-deployment.yaml file for a deployment without without creating the deployment:
$ kubectl create deployment nginx --image=nginx --dry-run=client -o yaml > nginx-deployment.yamlObjects, Objects Everywhere!
Kubernetes Objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster, and all objects have the below in common as illustrated in this graph:
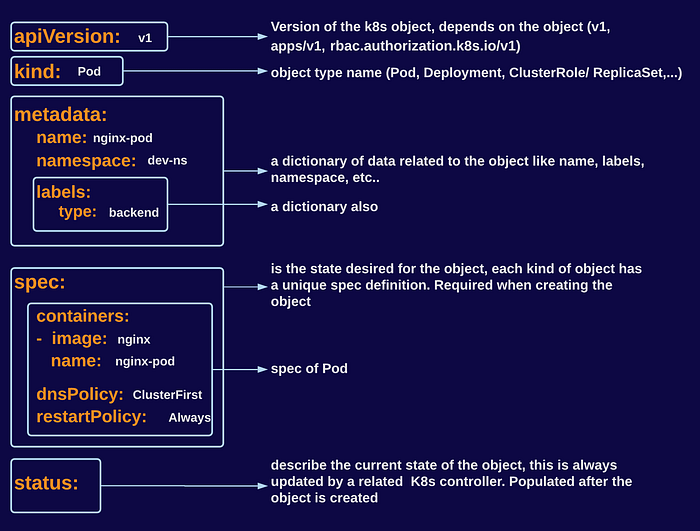
Pod
The smallest computing unit you can create in K8s, where it doesn’t deploy applications directly into nodes. However, here containers are encapsulated into Pod objects.
A pod can have one or more containers, and containers will share networking and resources within the same pod. So instead of having to run images separately in Docker, and have to set up volumes and networks, while also monitoring the state of the dependent container––don’t sweat it. Kubernetes can do this for us.
pod-1 in the below diagram has a NodeJS application that depends on MongoDB for storage, and Redis for caching. The NodeJS application will be able to access both containers with the networking features provided by the Pod. Whereas pod-2 only contains one application running inside a container, which is mostly the case for Pods, unless you need a helper tool for your application in the same pod as pod-1.
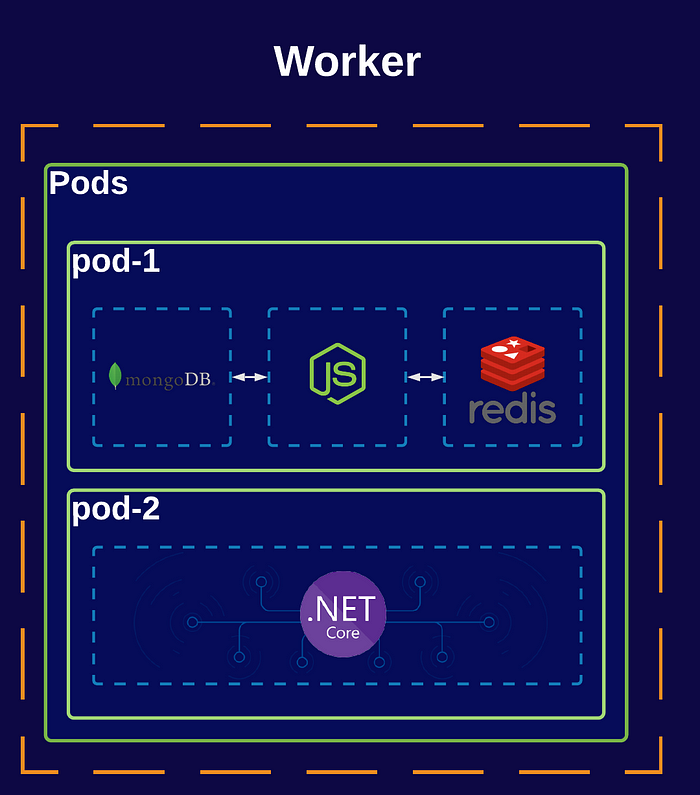
Pods are by nature ephemeral, meaning you can only expect one to last for a limited time. This means that when a pod is terminated or deleted, it doesn’t replace itself––for this reason, it’s recommended to have Pods inside a replica set, or for deployment to have self-healing options.
ReplicaSet
To maintain stable and self-healing Pods, you can use ReplicaSet: it ensures the number of desired Pods are met and always running at a given time.
ReplicaSet is defined by specifying replicas (the number of Pods to replicate), a pod template and an extra field called selector which is used to identify new Pods with the same selectors to acquire them.
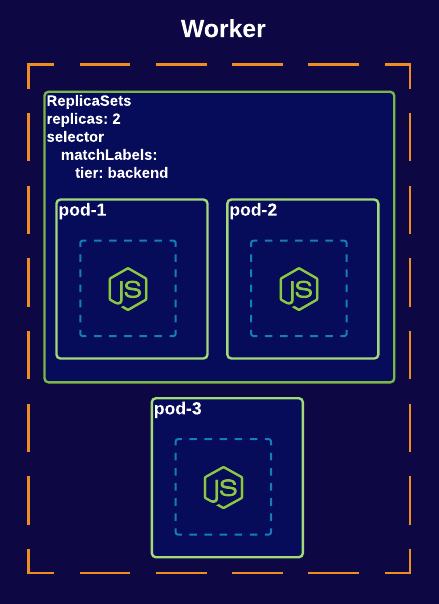
As you can see in the above diagram, ReplicaSet has two replicas: that’s why we have two Pods created for this replica with a tier selector. If for some reason pod-1/2 were to be terminated, the replica set will make sure to initialize a new pod to maintain the correct and required number of replicas. Whereas if pod-3 were terminated, it would be gone forever.
Below is a sample ReplicaSet manifest:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: be
labels:
app: customer-svc
tier: backend
spec:
replicas: 2
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: customer
image: customer-svcDeployment
Creating applications or services is not a one-time process: our applications will always evolve and change. When we deploy a version of our application, we need a mechanism to update the containerized applications automatically, as doing this manually is an overwhelming process (notably error-prone, and time-consuming…), particularly if you have tens, or many hundreds, of services. The deployment is a higher object in the hierarchy, as demonstrated in the diagram below. We should define the deployment to encapsulate replica sets and pods: its controller gives it the ability to monitor, manage and maintain the desired state of the application we want to deploy.
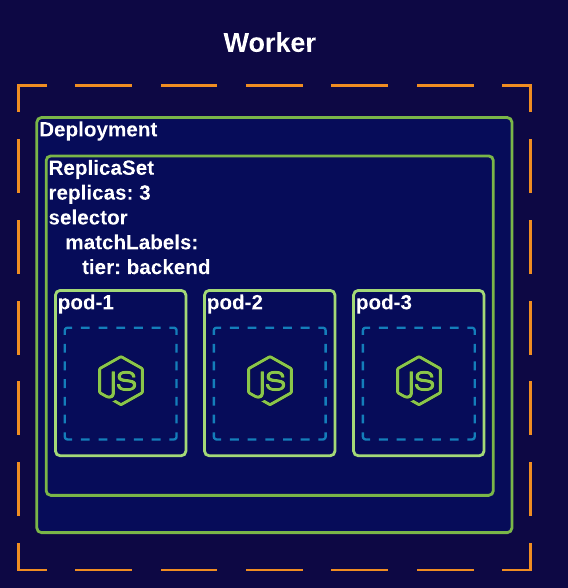
apiVersion: apps/v1
kind: Deployment
metadata:
name: be-deployment
labels:
app: customer-svc
tier: backend
spec:
replicas: 3
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: customer
image: customer-svcDeployment provides a rollback mechanism in case it’s not stable, or an error is occurring: all rollout histories are kept and logged in the system, where you can roll back anytime to a specific version. You describe your desired state in a Deployment, and the Deployment Controller changes the actual state to match the desired state at a controlled rate. You can define Deployments to create new ReplicaSets or to remove existing Deployments and adopt all their resources with new Deployments. Some great information about Deployment can be found in this link.
Namespace
Namespaces provide isolation among objects, where you can have some kind of virtual clusters in your K8s cluster. As shown in the diagram below, there are two custom namespaces created dev-ns and prod-ns.
By having this separation, you could restrict access to the production cluster objects for administrators and infrastructure managers, where developers can access only the objects found under the dev-ns.
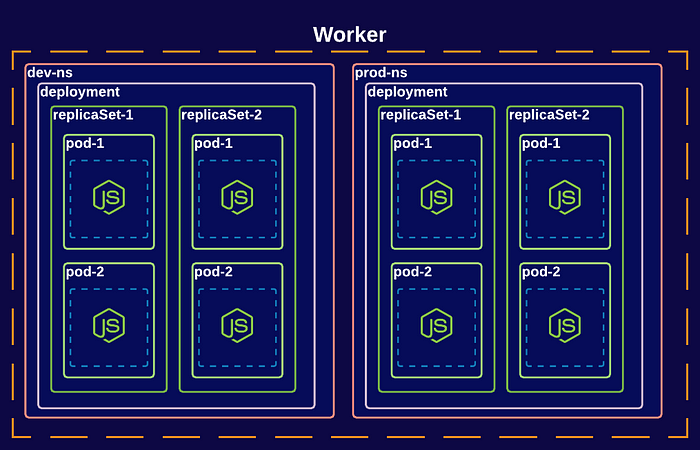
Three namespaces are always created when having a K8s cluster: default, kube-system, and kube-public. While you can create objects under these namespaces, it’s best practice and recommended to create your own namespaces.
When creating an object, if a namespace is not provided, the default will be assigned to the new object, or you can specify the namespace either in the metadata object definition or as a flag for the kubectl command.
$kubectl create namespace dev-ns //create a namespace$kubectl run nginx --image nginx --namespace dev-ns //create and run an nginx pod under dev-ns namespaceOr specify the namespace in the object definition(line 4):
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: dev-ns
name: be-deployment
labels:
app: customer-svc
tier: backend
spec:
replicas: 3
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: customer
image: customer-svcServices
Services are used to expose and enable network access to Pods. Pods are selected using their labels, so when the network is enabled on a service, it will select all the Pods matching the specified selector.
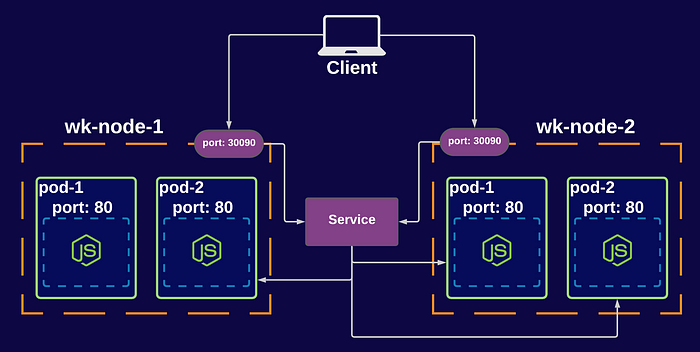
Use expose command to enable pod networking access and create a service:
$kubectl run nginx –replicas=3 –labels="run=service-example" –image=nginx –port=8080$kubectl expose deployment nginx --type=ClusterIP --name=nginx-serviceTypes of Services
- ClusterIP: The default service if there is no type specified. Pods are only accessible inside the cluster.
- NodePort: The service is exposed on the IP of the node using a static port. Clients send requests to the IP address of a node on one or more node port values that are specified by the Service.
- LoadBalancer: Used to expose the service externally using a cloud provider’s load balancer. Clients send requests to the IP address of a network load balancer.
- ExternalName: Internal clients use the DNS name of a Service as an alias for an external DNS name.
- Headless: You can use a headless service in situations where you want a Pod grouping, but don’t need a stable IP address.
And that’s a wrap! Hope you enjoyed my guide to the core concepts in Kubernetes, and are ready to start tinkering with your own projects.
Resources
- Diagrams created using Lucid Charts ✏️
- https://kubernetes.io
- Kubectl
- Deployments